

In any case, irrespective of your choice to use an integrated or separate sub-systems, we believe that solid advantages arise if you decide to follow the more painful road of using a single data source for all sub-systems.
Painful road? Clearly, with this approach we need more time and effort to design the proper data source, not only because the particular needs of each subsystem must be taken into account, but also because we have to also consider their evolution over time. Building extensible databases is definitely challenging, especially for data entities that are commonly used by many sub-systems, such as the information about the identity of a Person or the Price of an asset. But the result is worth the effort, as it simplifies many customer processes and leads to having systems with fully integrated data, which remain scalable and easy to maintain.
Key Benefits
- One data source means easier maintenance each time we update an application
- No extra effort or concerns when new modules are purchased
- Common interfaces for importing data from external systems
- Natural data de-duplication
- Common Data extraction
See here for a more detailed explanation:
Key benefits from using a single data source from Systemic
Example: Fund administration
Let’s check out these advantages, using an example from the fund administration industry.
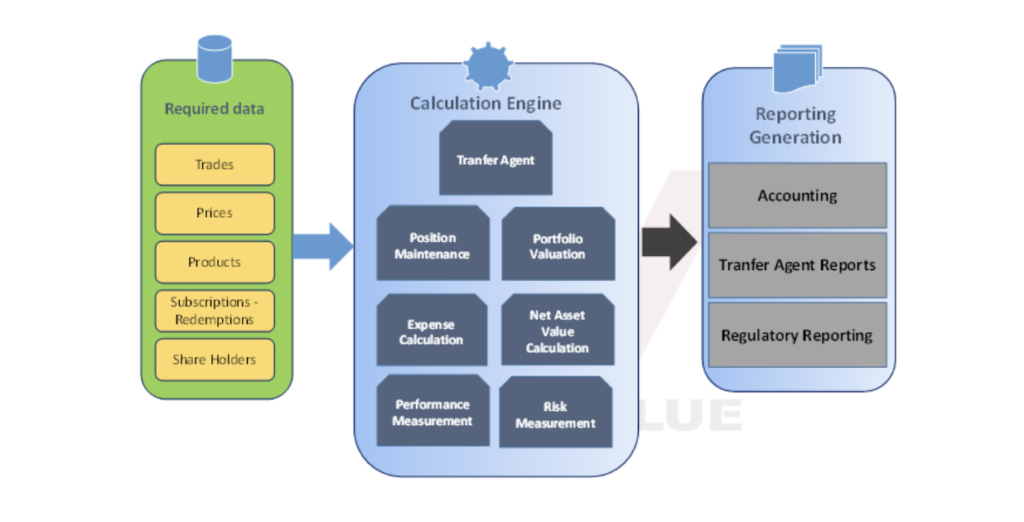
The Fund administration industry has become more complicated and demanding than ever. Several independent services are acquired, to complete daily operations, offering customized reporting to Fund Managers, Fund Advisors, and Shareholders. Services include NAV calculation, Fee monitoring, Performance measurement, Accounting, and Risk Management to name a few. On business level, all these procedures are independent from one another, however, they all require common data as input, or they send their results to other services, to be used as input.
For example, let’s take Trades and Prices, two entities that can be inserted in two ways, either manually or from an automated uploading process. In either case, each trade or price is inserted only once, to a single database, with a unique key identification; this piece of data will be visible to all the subsystems instantly. In another example, Positions and Valuations will be calculated and stored only once, no matter how many times they will be used in the future as input for Portfolio management and NAV calculation.
Even if a company decides, at a later stage, to purchase an accounting module, all the data that are required for its activation will have already been inserted to the common data source, so no extra work needs to be done from the IT Manager or the Database Administrators, as there are no extra data sources or new application to be installed.



